Build Rag With Local Data Code
Build Rag With Local Data Code - In this blog post we will learn how to do retrieval augmented generation (rag) using local resources in.net! So, in this post, we will build a fully local rag application to avoid sending private information to the llm. In this tutorial, we’ll be building rag from scratch — no langchain or llama index. We'll use postgresql to store documents and ollama to host a local. By utilizing retrieval and generative functions to build the rag system, this project adds another layer by embedding audio capability in several steps. Building and deploying your first rag. Text retrieval happens before generating an answer. Rag over complex real word docs ft. You can find all the. For example, if you ask, ‘what are the key. Many ai vendors now offer rag tools along with their models, which allow agencies to identify and build quality data pipelines, briggs says. Text retrieval happens before generating an answer. So, in this post, we will build a fully local rag application to avoid sending private information to the llm. Deepseek r1 comes in sizes. We'll use postgresql to store documents and ollama to host a local. Opting for a local rag system means ensuring that your data never leaves your premises, a crucial aspect for entities dealing with sensitive or proprietary information. By utilizing retrieval and generative functions to build the rag system, this project adds another layer by embedding audio capability in several steps. Instead, i wanted to show. Change the data_directory in the python code according to which data you want to use for rag. The retriever enables the search functionality for fetching the most relevant chunks of content based on a query. Text retrieval happens before generating an answer. In the console, a local ip. How to build a rag using langchain ollama and streamlit how to build a rag using langchain ollama and streamlit 2. Everyone is talking about rag, but what is. We'll use postgresql to store documents and ollama to host a local. So, in this post, we will build a fully local rag application to avoid sending private information to the llm. We'll use postgresql to store documents and ollama to host a local. Local rag pipeline we're going to build: Text retrieval happens before generating an answer. Building local rag solutions with deepseek: In this tutorial, we’ll be building rag from scratch — no langchain or llama index. I've seen a big uptick in users in r/localllama asking. Opting for a local rag system means ensuring that your data never leaves your premises, a crucial aspect for entities dealing with sensitive or proprietary information. For example, if you ask, ‘what are the key.. By utilizing retrieval and generative functions to build the rag system, this project adds another layer by embedding audio capability in several steps. Local rag pipeline we're going to build: For example, if you ask, ‘what are the key. We'll use postgresql to store documents and ollama to host a local. All the way from pdf ingestion to chat with. Text retrieval happens before generating an answer. By utilizing retrieval and generative functions to build the rag system, this project adds another layer by embedding audio capability in several steps. Instead, i wanted to show. We've been building r2r (please support us w/ a star here), a framework for rapid development and deployment of rag pipelines. Local rag pipeline we're. We've been building r2r (please support us w/ a star here), a framework for rapid development and deployment of rag pipelines. How to build a rag using langchain ollama and streamlit how to build a rag using langchain ollama and streamlit 2. Now, this is not because those libraries are insufficient, far from it. In the console, a local ip.. By utilizing retrieval and generative functions to build the rag system, this project adds another layer by embedding audio capability in several steps. The first run may take a while. Building and deploying your first rag. How to build a rag using langchain ollama and streamlit how to build a rag using langchain ollama and streamlit 2. We've been building. How to build a rag using langchain ollama and streamlit how to build a rag using langchain ollama and streamlit 2. The script sets up a rag pipeline, which ensures that: Opting for a local rag system means ensuring that your data never leaves your premises, a crucial aspect for entities dealing with sensitive or proprietary information. All designed to. In this tutorial, we’ll be building rag from scratch — no langchain or llama index. We've been building r2r (please support us w/ a star here), a framework for rapid development and deployment of rag pipelines. The first run may take a while. You can find all the. How to build a rag using langchain ollama and streamlit how to. In this tutorial, we’ll be building rag from scratch — no langchain or llama index. Many ai vendors now offer rag tools along with their models, which allow agencies to identify and build quality data pipelines, briggs says. All designed to run locally on a nvidia gpu. The script sets up a rag pipeline, which ensures that: In the console,. Opting for a local rag system means ensuring that your data never leaves your premises, a crucial aspect for entities dealing with sensitive or proprietary information. By utilizing retrieval and generative functions to build the rag system, this project adds another layer by embedding audio capability in several steps. For example, if you ask, ‘what are the key. We'll use postgresql to store documents and ollama to host a local. Instead, i wanted to show. We've been building r2r (please support us w/ a star here), a framework for rapid development and deployment of rag pipelines. Building and deploying your first rag. The first run may take a while. All the way from pdf ingestion to chat with pdf style features. In the console, a local ip. Local rag pipeline we're going to build: Now, this is not because those libraries are insufficient, far from it. Text retrieval happens before generating an answer. The retriever enables the search functionality for fetching the most relevant chunks of content based on a query. Rag over complex real word docs ft. I've seen a big uptick in users in r/localllama asking.
RAG Explained Papers With Code

Build RAG Application Using a LLM Running on Local Computer with Ollama
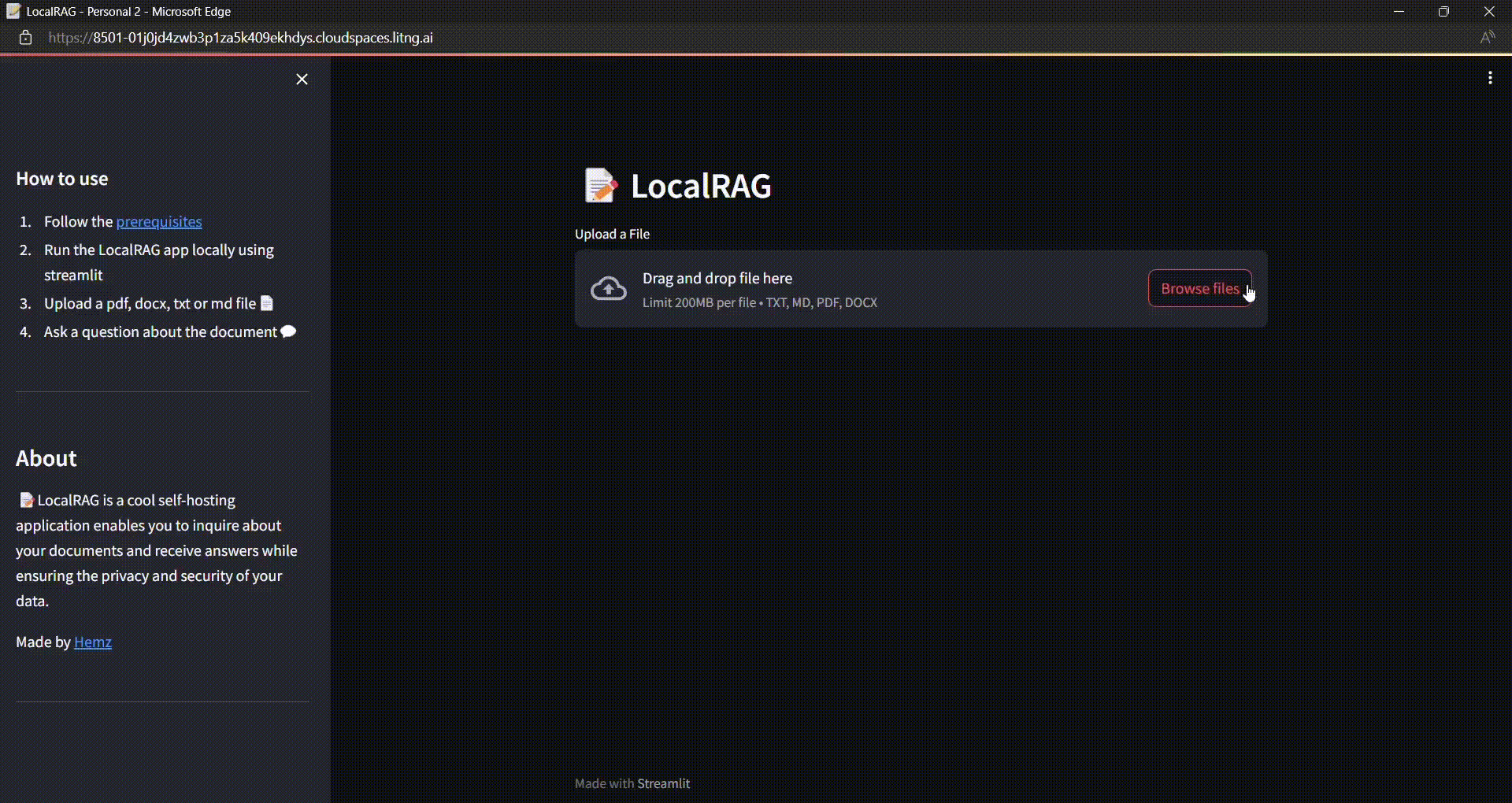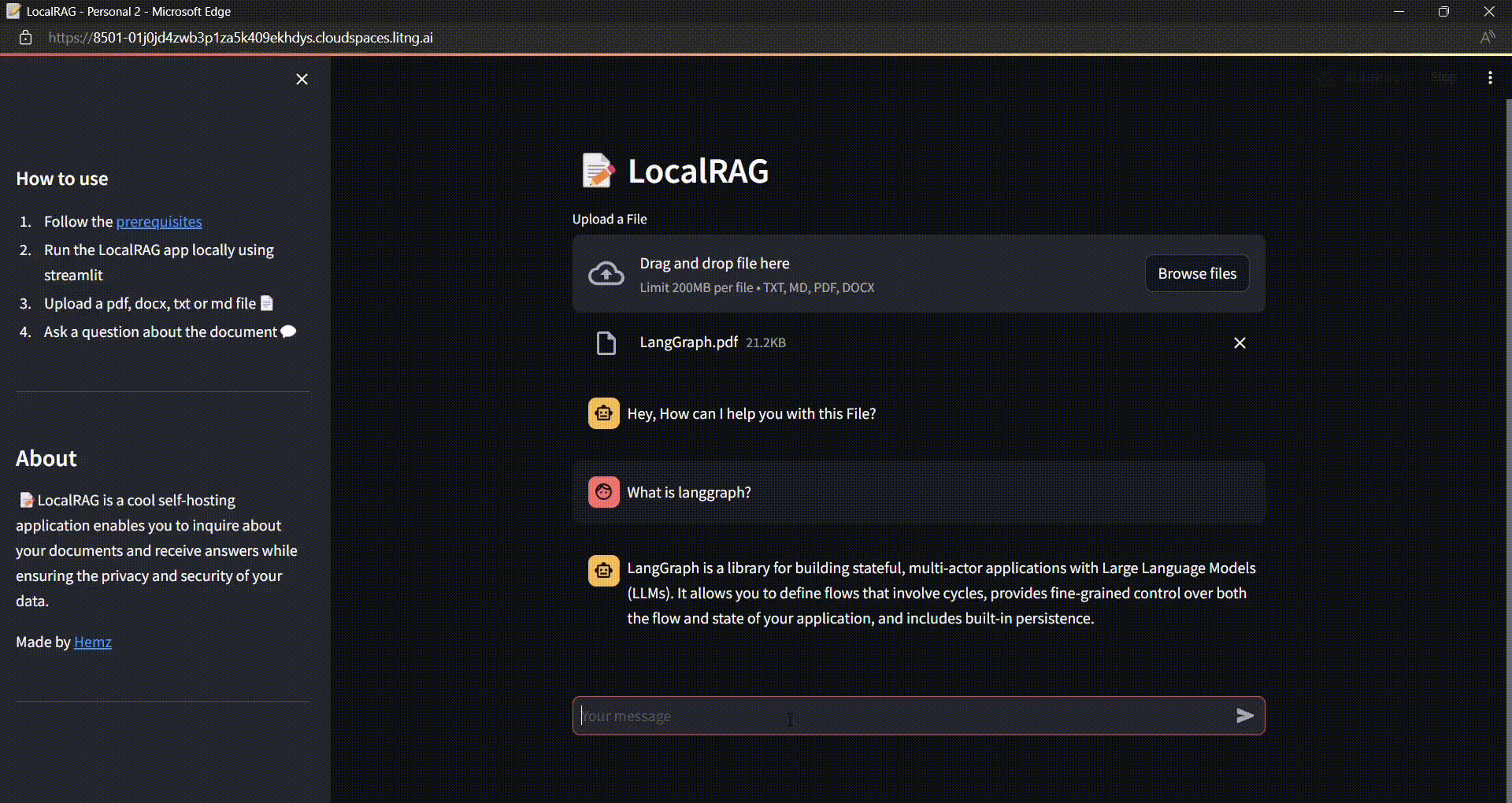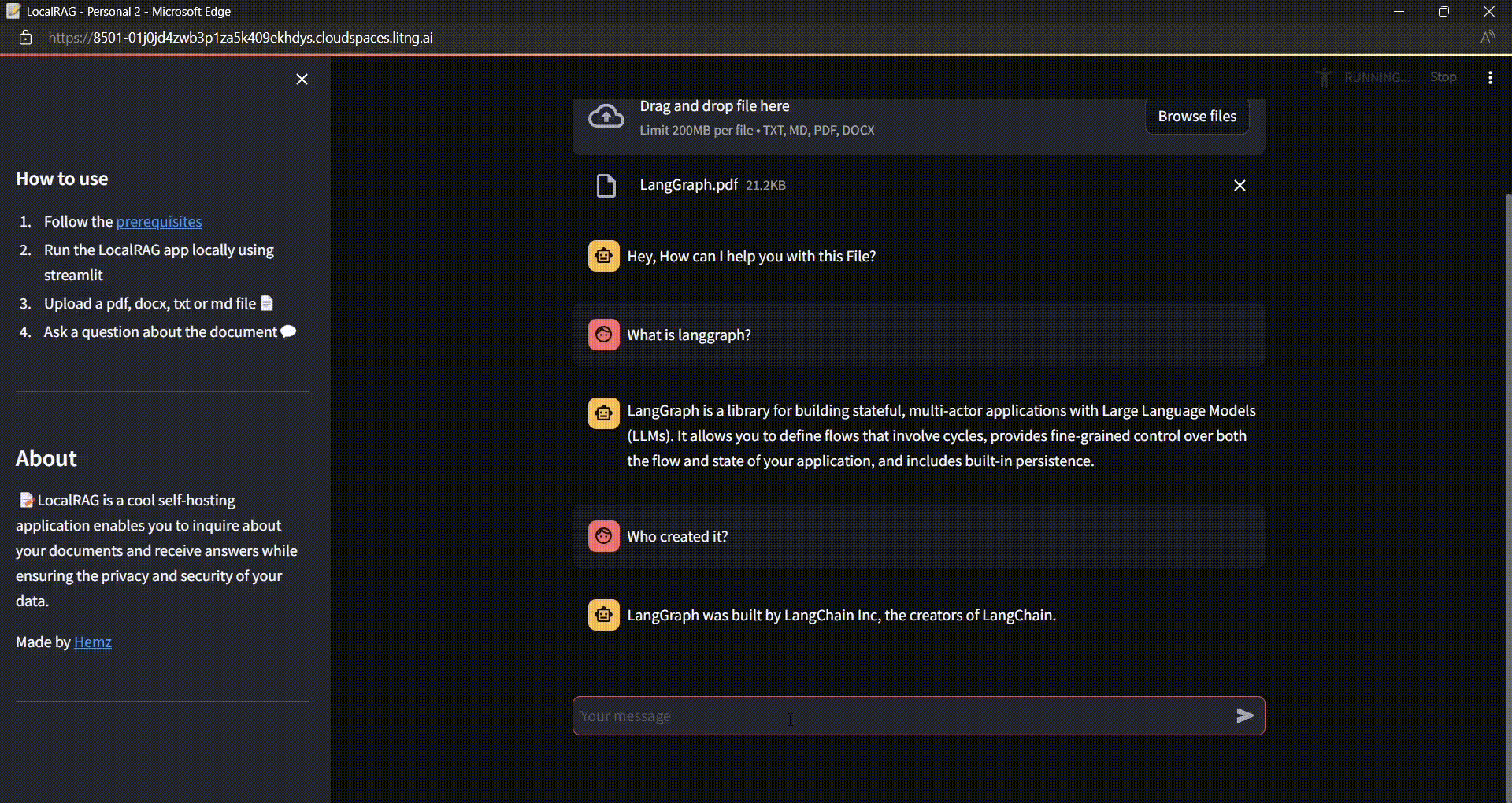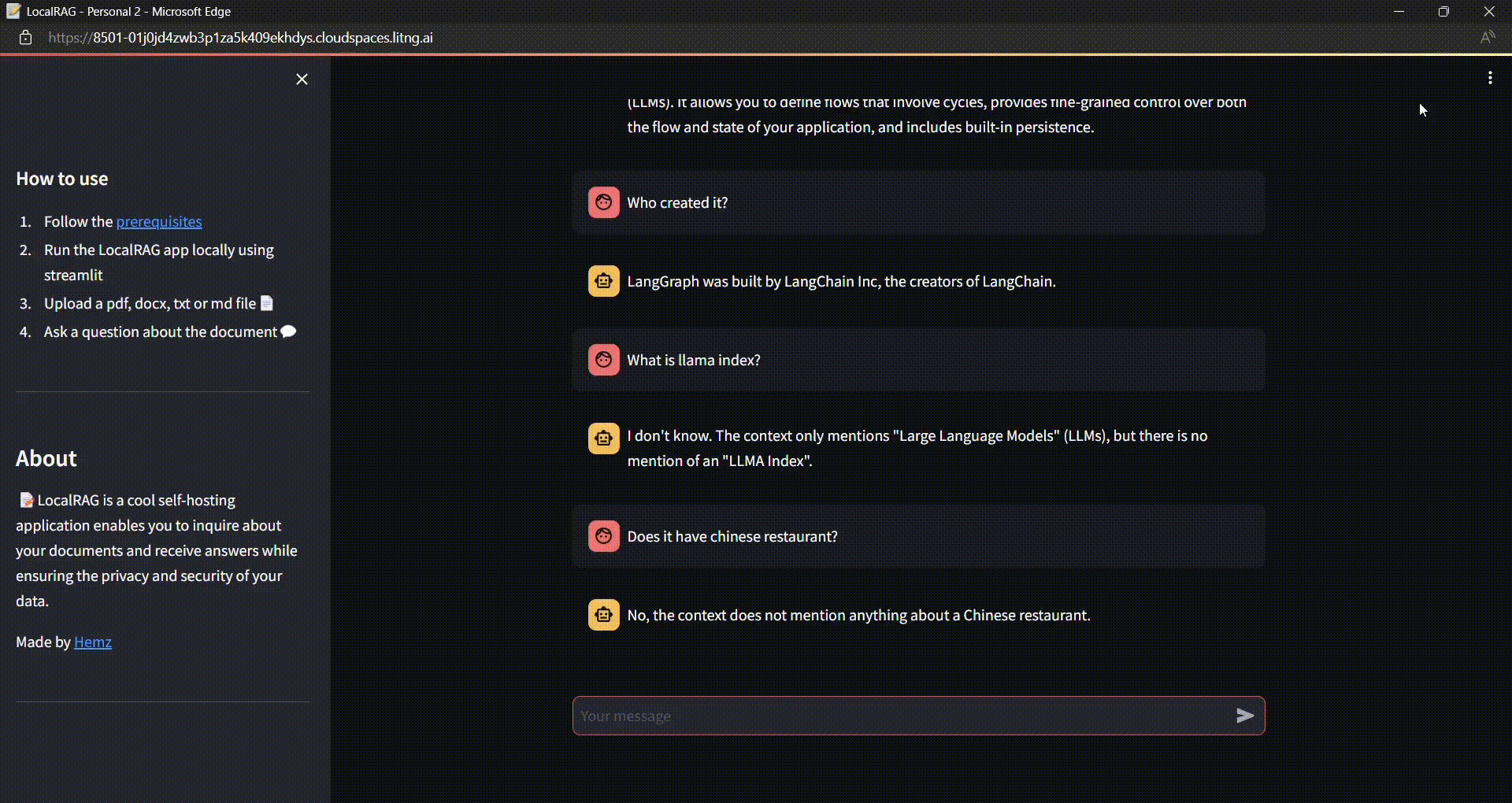
Build a Secure Local RAG Application with Chat History using LangChain
Building RAG application using Langchain 🦜, OpenAI 🤖, FAISS by

Install GraphRAG Locally Build RAG Pipeline with Local and Global
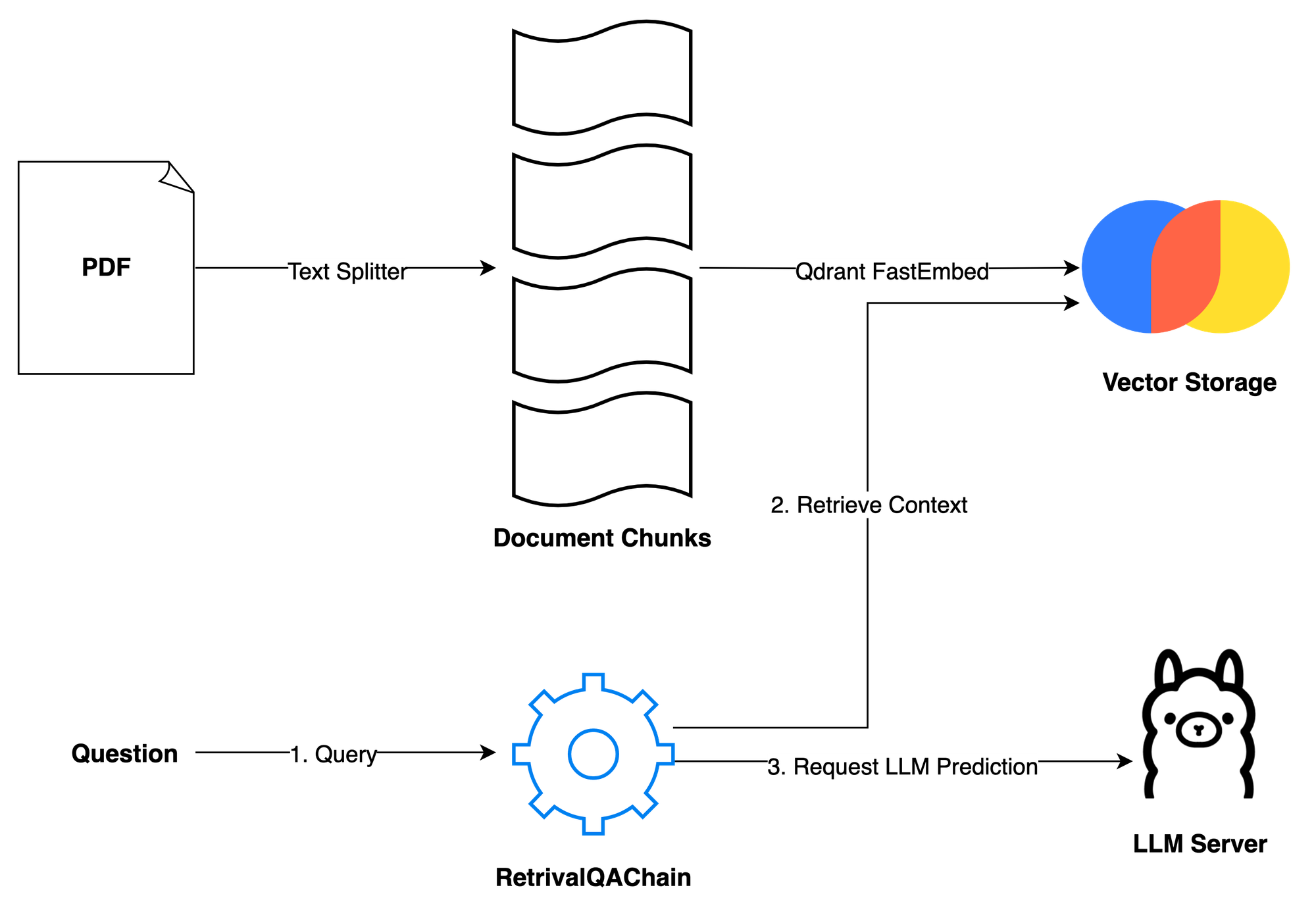
Build your own RAG and run it locally Langchain + Ollama + Streamlit

Local RAG From Scratch. Develop and deploy an entirely local… by Joe


Building a Local RAG api with LlamaIndex, Qdrant, Ollama and FastAPI

Build a ChatBot Using Local LLM. Exploring RAG using Ollama, LangChain
Many Ai Vendors Now Offer Rag Tools Along With Their Models, Which Allow Agencies To Identify And Build Quality Data Pipelines, Briggs Says.
You Can Find All The.
So, In This Post, We Will Build A Fully Local Rag Application To Avoid Sending Private Information To The Llm.
Deepseek R1 Comes In Sizes.
Related Post: