Build Rag With Local Data
Build Rag With Local Data - All the way from pdf ingestion to chat with pdf style features. All designed to run locally on a nvidia gpu. The first run may take a while. Learn key steps, tools, and best practices for optimal performance. Change the data_directory in the python code according to which data you want to use for rag. Rag combines the best of these approaches while mitigating their limitations. In the console, a local ip. Fetching relevant documents or data from a. This can really help you to understand the. A further characteristic that marks this document as special is the meticulous scrutiny of varied aspects related to build a fully local reasoning deepseek r1 rag with ollama. All designed to run locally on a nvidia gpu. Using high level libraries can build a demo faster, but they hide how things work inside. This blog post will guide you through building your own local rag system using tools like ollama, llama3, and langchain, empowering you to create an ai solution that is. Build local rag solutions with deepseek. Moreover, our full rag crash course discusses rag from basics to beyond: By utilizing retrieval and generative functions to build the rag system, this project adds another layer by embedding audio capability in several steps. In the console, a local ip. This can really help you to understand the. The first run may take a while. Change the data_directory in the python code according to which data you want to use for rag. All the way from pdf ingestion to chat with pdf style features. Opting for a local rag system means ensuring that your data never leaves your premises, a crucial aspect for entities dealing with sensitive or proprietary information. In this blog post we will learn how to do retrieval augmented generation (rag) using local resources in.net! By setting up a. Learn how to build local retrieval. By setting up a local rag application with tools like ollama, python, and chromadb, you can enjoy the benefits of advanced language models while maintaining control over your data and. Change the data_directory in the python code according to which data you want to use for rag. All the way from pdf ingestion to. This can really help you to understand the. Using high level libraries can build a demo faster, but they hide how things work inside. Fetching relevant documents or data from a. Opting for a local rag system means ensuring that your data never leaves your premises, a crucial aspect for entities dealing with sensitive or proprietary information. In the console,. By utilizing retrieval and generative functions to build the rag system, this project adds another layer by embedding audio capability in several steps. All designed to run locally on a nvidia gpu. This blog post will guide you through building your own local rag system using tools like ollama, llama3, and langchain, empowering you to create an ai solution that. By utilizing retrieval and generative functions to build the rag system, this project adds another layer by embedding audio capability in several steps. Local rag pipeline we're going to build: By setting up a local rag application with tools like ollama, python, and chromadb, you can enjoy the benefits of advanced language models while maintaining control over your data and.. By setting up a local rag application with tools like ollama, python, and chromadb, you can enjoy the benefits of advanced language models while maintaining control over your data and. Change the data_directory in the python code according to which data you want to use for rag. By following the steps outlined above, you can build a powerful rag application. Local rag pipeline we're going to build: In this blog post we will learn how to do retrieval augmented generation (rag) using local resources in.net! By setting up a local rag application with tools like ollama, python, and chromadb, you can enjoy the benefits of advanced language models while maintaining control over your data and. By utilizing retrieval and generative. All designed to run locally on a nvidia gpu. In the console, a local ip. By following the steps outlined above, you can build a powerful rag application capable of answering questions based on indexed content. Fetching relevant documents or data from a. Build local rag solutions with deepseek. Opting for a local rag system means ensuring that your data never leaves your premises, a crucial aspect for entities dealing with sensitive or proprietary information. The first run may take a while. Local rag pipeline we're going to build: By utilizing retrieval and generative functions to build the rag system, this project adds another layer by embedding audio capability. Learn how to build local retrieval. A further characteristic that marks this document as special is the meticulous scrutiny of varied aspects related to build a fully local reasoning deepseek r1 rag with ollama. Opting for a local rag system means ensuring that your data never leaves your premises, a crucial aspect for entities dealing with sensitive or proprietary information.. All designed to run locally on a nvidia gpu. Local rag pipeline we're going to build: In the console, a local ip. All the way from pdf ingestion to chat with pdf style features. In this blog post we will learn how to do retrieval augmented generation (rag) using local resources in.net! The first run may take a while. Local rag addresses this challenge by processing and generating responses entirely within a secure local environment, ensuring data privacy and security. This blog post will guide you through building your own local rag system using tools like ollama, llama3, and langchain, empowering you to create an ai solution that is. By setting up a local rag application with tools like ollama, python, and chromadb, you can enjoy the benefits of advanced language models while maintaining control over your data and. Opting for a local rag system means ensuring that your data never leaves your premises, a crucial aspect for entities dealing with sensitive or proprietary information. A further characteristic that marks this document as special is the meticulous scrutiny of varied aspects related to build a fully local reasoning deepseek r1 rag with ollama. Learn how to build local retrieval. The rag framework works in two key steps: By following the steps outlined above, you can build a powerful rag application capable of answering questions based on indexed content. Rag combines the best of these approaches while mitigating their limitations. Build local rag solutions with deepseek.
Install GraphRAG Locally Build RAG Pipeline with Local and Global

How to Build a Local OpenSource LLM Chatbot With RAG by Dr. Leon

Build a ChatBot Using Local LLM. Exploring RAG using Ollama, LangChain

Building a Local RAG api with LlamaIndex, Qdrant, Ollama and FastAPI
![Local RAG with Local LLM [HuggingFaceChroma] by Octaviopavon Medium](https://miro.medium.com/v2/resize:fit:1358/1*ikb78ftflysKB8thTwDL-Q.png)
Local RAG with Local LLM [HuggingFaceChroma] by Octaviopavon Medium
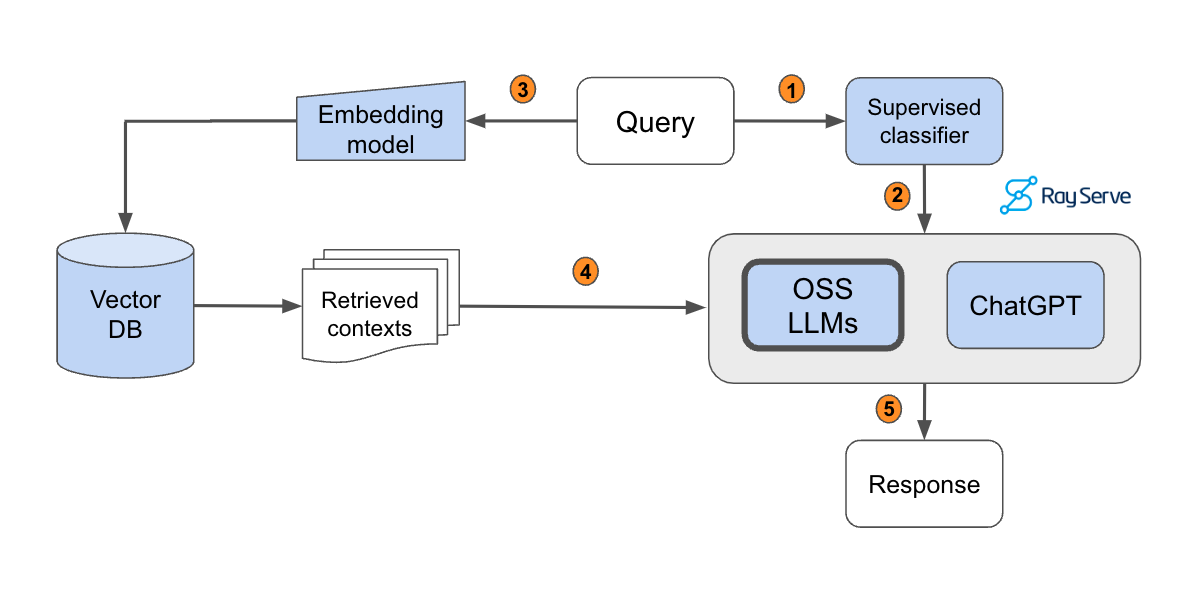
Build your own RAG and run it locally Langchain + Ollama + Streamlit

Building Local RAG Chatbots Without Coding Using LangFlow and Ollama
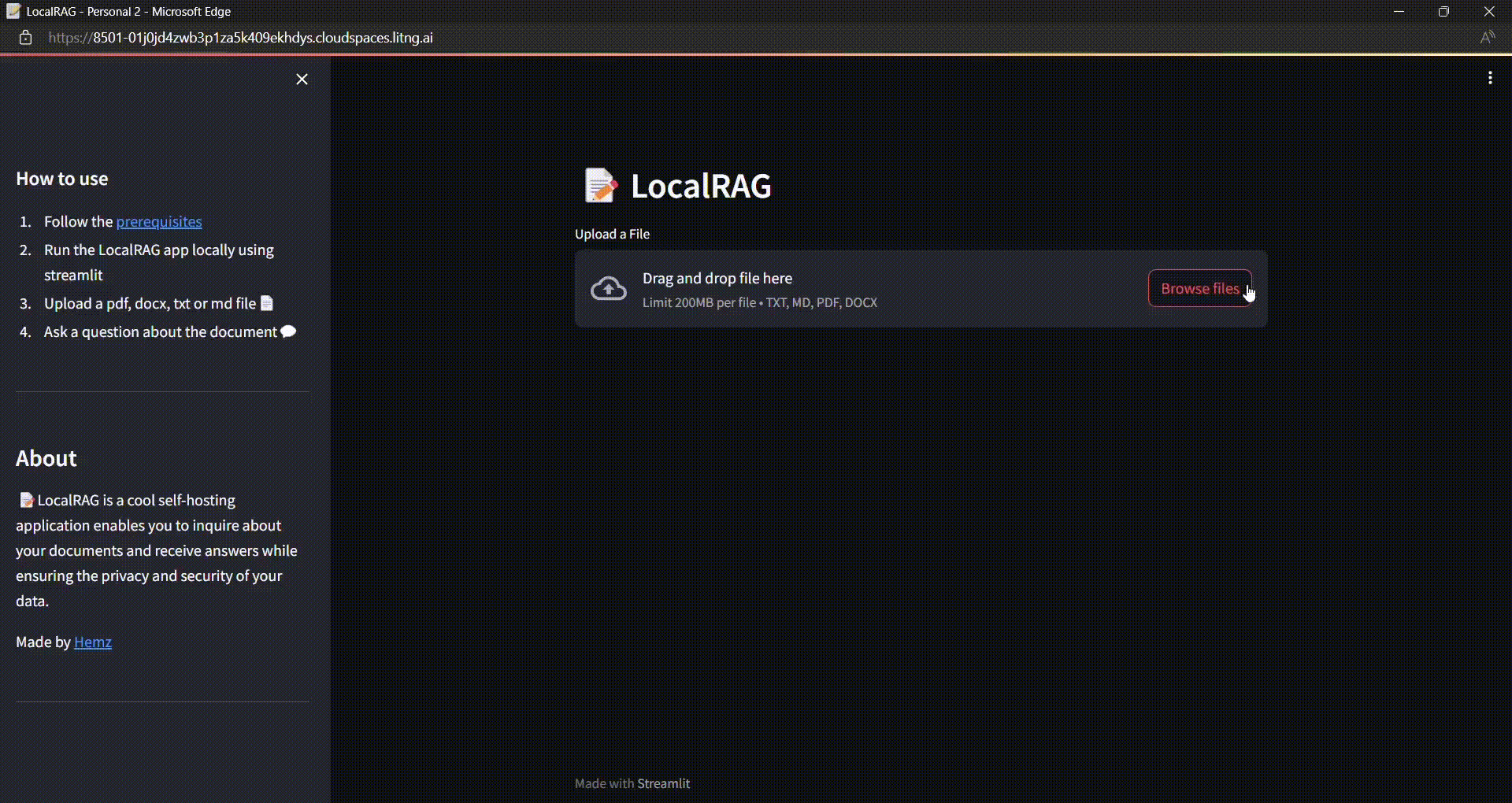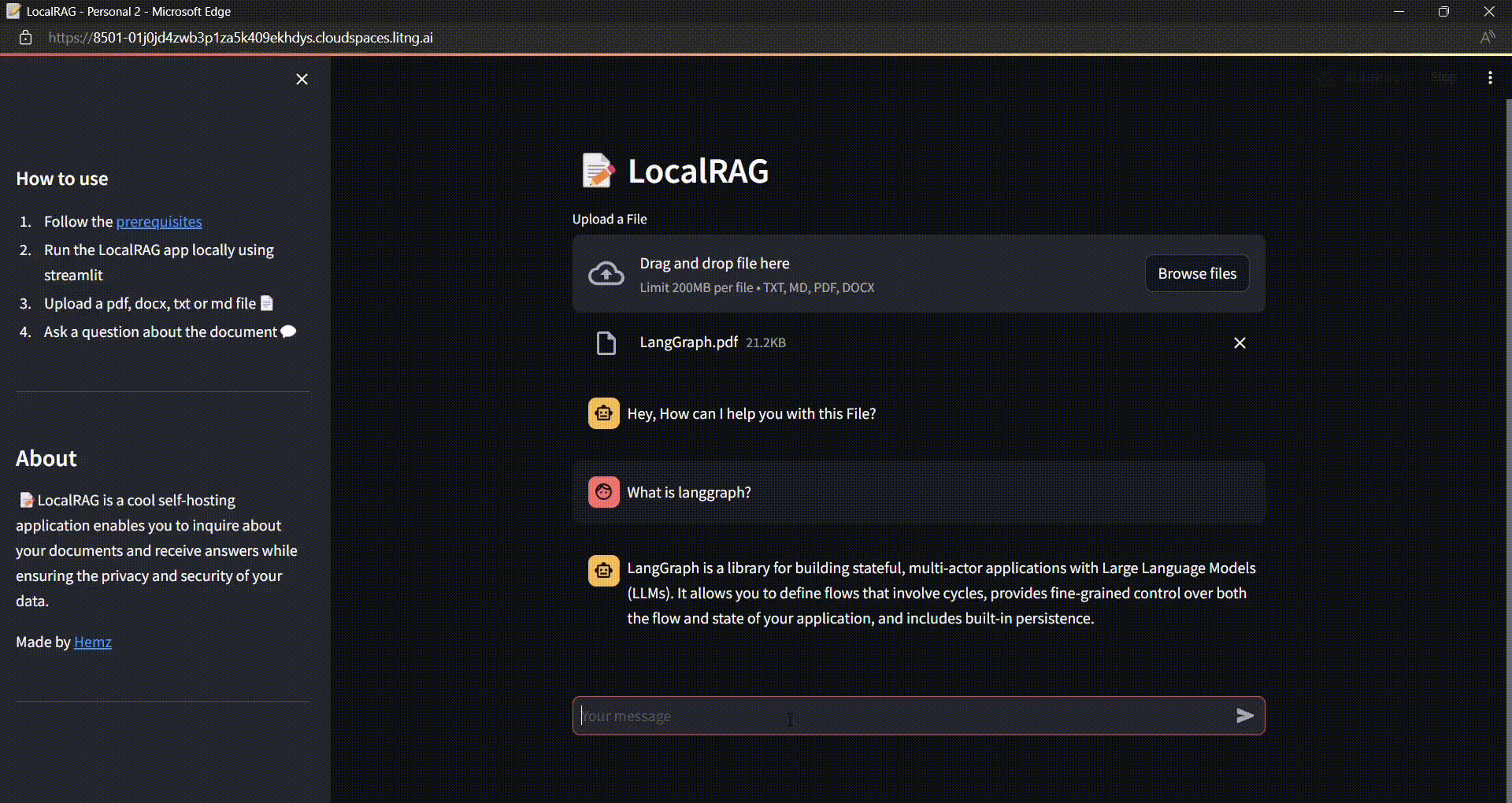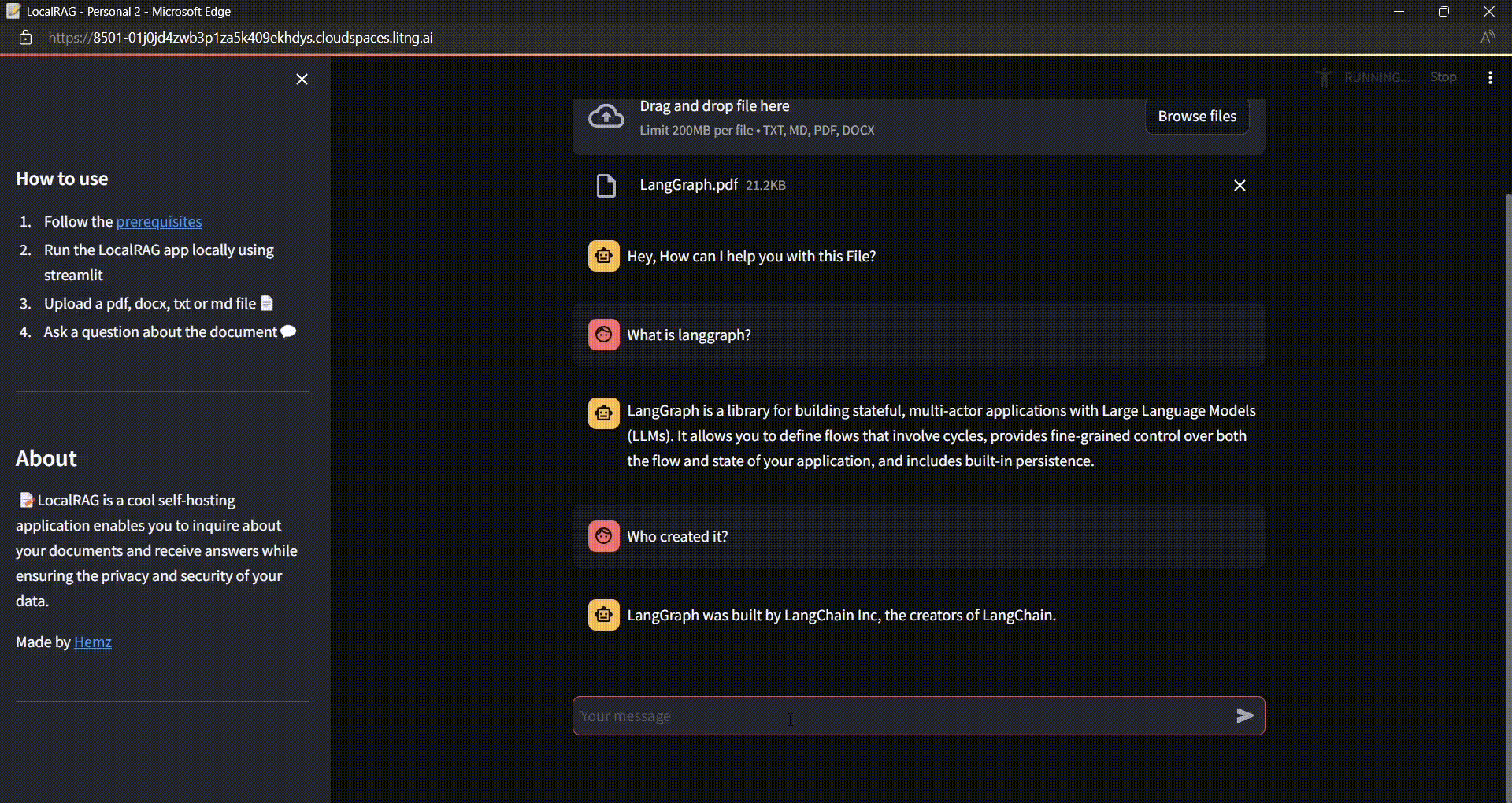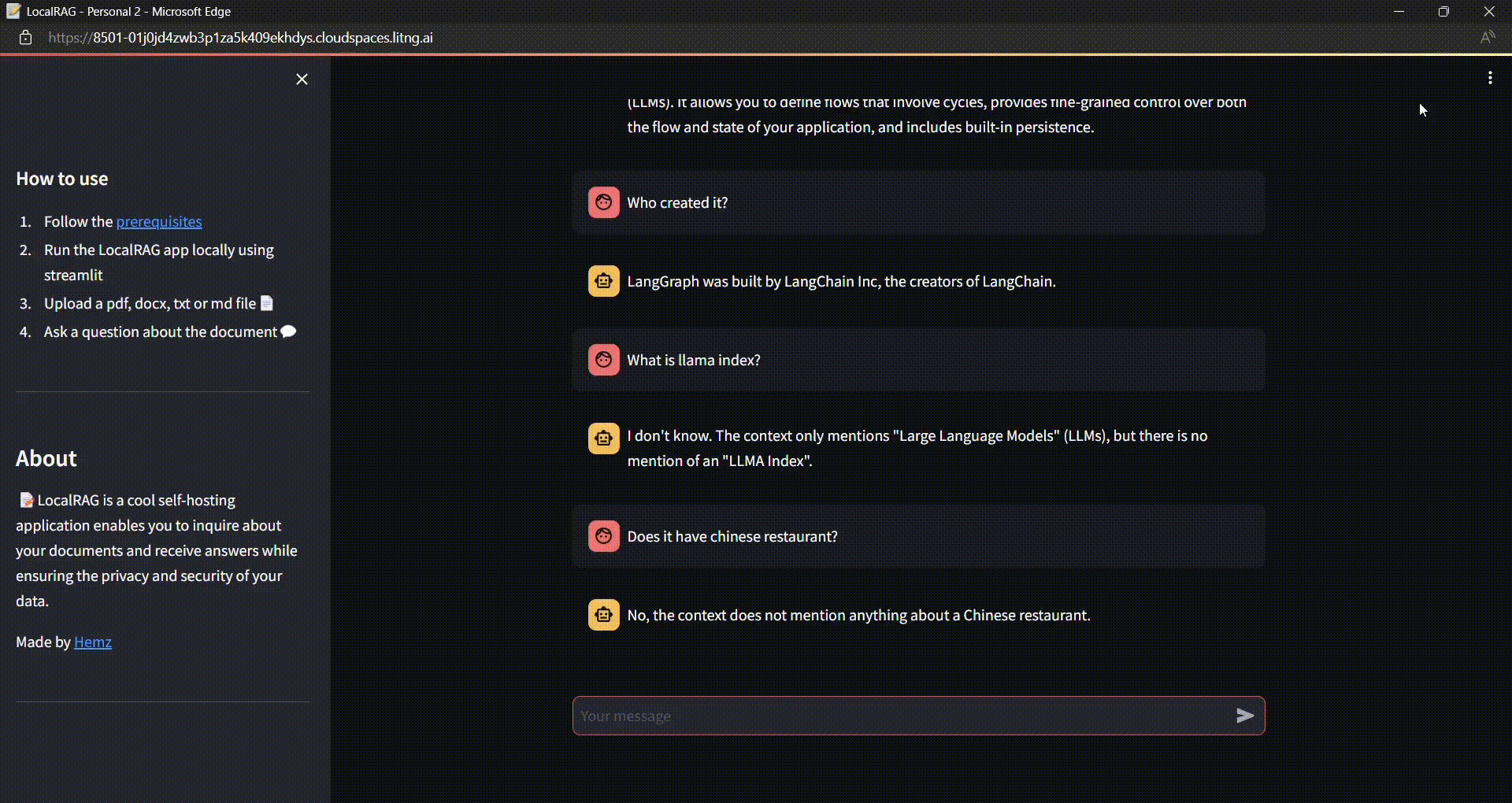
Build a Secure Local RAG Application with Chat History using LangChain
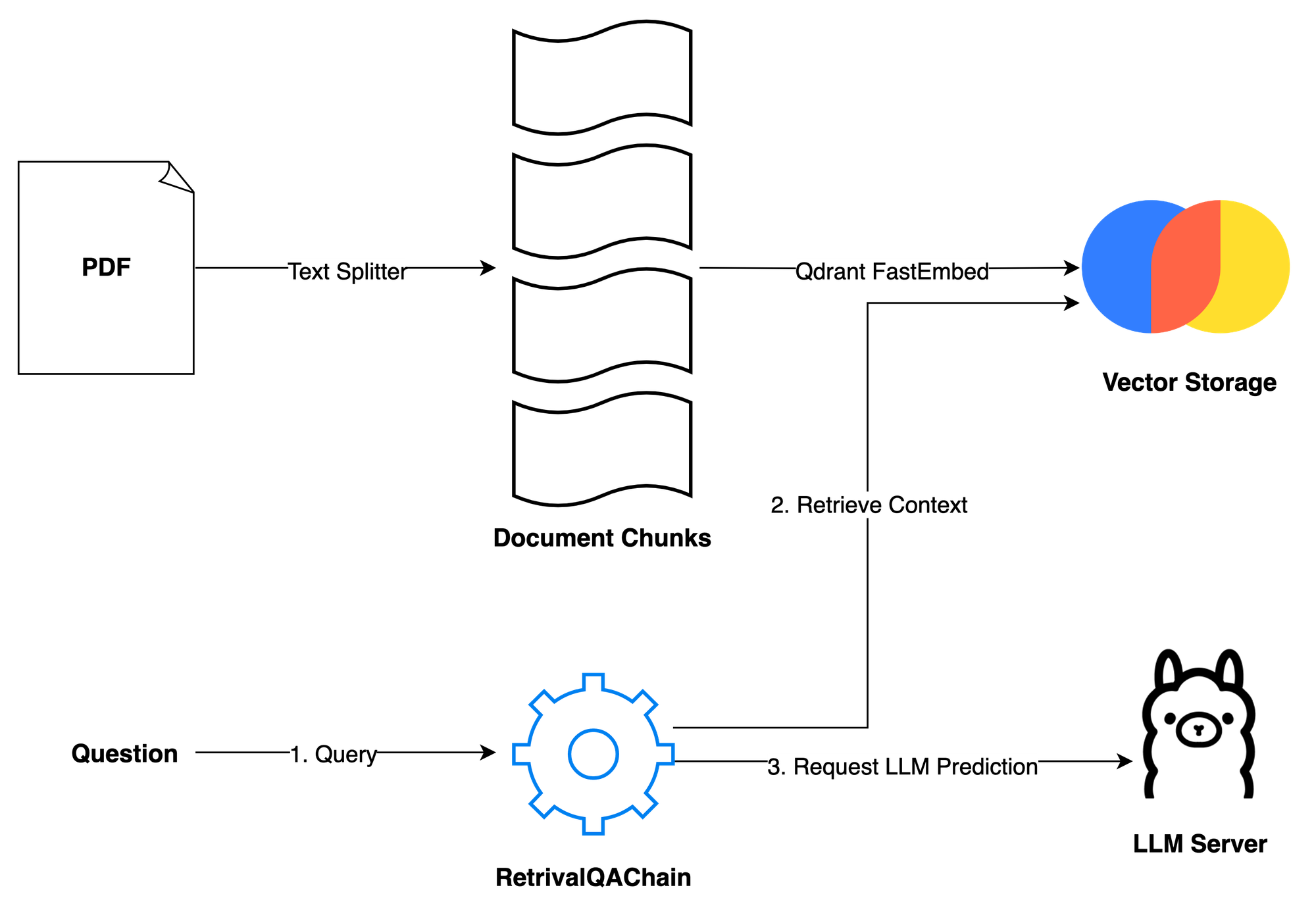
Build your own RAG and run it locally Langchain + Ollama + Streamlit
Building RAG application using Langchain 🦜, OpenAI 🤖, FAISS by
Change The Data_Directory In The Python Code According To Which Data You Want To Use For Rag.
Using High Level Libraries Can Build A Demo Faster, But They Hide How Things Work Inside.
Fetching Relevant Documents Or Data From A.
By Utilizing Retrieval And Generative Functions To Build The Rag System, This Project Adds Another Layer By Embedding Audio Capability In Several Steps.
Related Post: