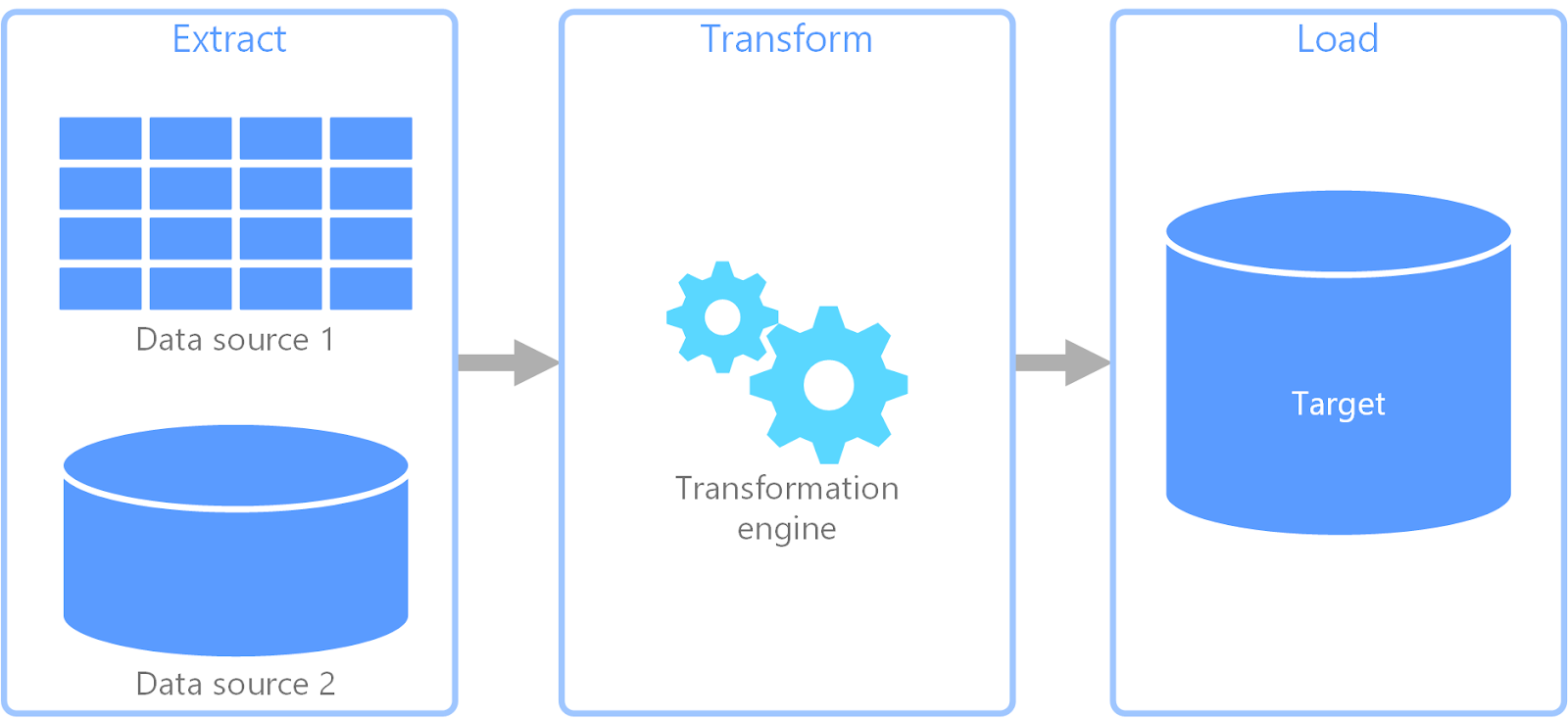
Building Etl Pipelines
Building Etl Pipelines - It's the series of steps and tools that automate the movement of data. Modern extract, transform, and load (etl) pipelines for data engineering have favored the python language for its broad range of uses and a large assortment of tools, applications, and open. With this knowledge of databricks’ architecture, it’s easier to examine the details involved in building databricks etl pipelines. In this comprehensive guide, we‘ll dive deep into the world of etl pipelines. The critical layer in the architecture is the delta. Dlt enables efficient ingestion for data engineers, python developers, data scientists and sql analysts. Design and implement technical, scalable solutions by adhering to the sdlc, coding standards, best practices, code performance ensuring high quality of code. In a large retail chain, stakeholders must. An etl (data extraction, transformation, loading) pipeline is a set of processes used to extract, transform, and load data from a source to a target. Data pipelines serve as the backbone of modern data architecture, facilitating the seamless flow of information from various sources to destinations for analysis and decision. The source of the data. Creation of snowflake task/pipe/stream for ingestion of data into raw layer of cdp (snowflake) from s3 as a source. Modern extract, transform, and load (etl) pipelines for data engineering have favored the python language for its broad range of uses and a large assortment of tools, applications, and open. Extensive experience in building etl pipelines using. Data pipelines serve as the backbone of modern data architecture, facilitating the seamless flow of information from various sources to destinations for analysis and decision. The critical layer in the architecture is the delta. Design and implement technical, scalable solutions by adhering to the sdlc, coding standards, best practices, code performance ensuring high quality of code. An etl (data extraction, transformation, loading) pipeline is a set of processes used to extract, transform, and load data from a source to a target. In this blog, we will dive into the implementation of a robust etl pipeline using python, a powerful and versatile programming language that offers an array of libraries and. Dlt enables efficient ingestion for data engineers, python developers, data scientists and sql analysts. The critical layer in the architecture is the delta. Data pipelines serve as the backbone of modern data architecture, facilitating the seamless flow of information from various sources to destinations for analysis and decision. In this post, we’ll walk through the process of building a robust etl (extract, transform, load) pipeline using apache airflow, google cloud storage (gcs), bigquery, and.. In this post, we’ll walk through the process of building a robust etl (extract, transform, load) pipeline using apache airflow, google cloud storage (gcs), bigquery, and. The focus of this blog post is to demonstrate how easily you can implement these streaming etl pipelines in apache kafka®. With this knowledge of databricks’ architecture, it’s easier to examine the details involved. An etl (data extraction, transformation, loading) pipeline is a set of processes used to extract, transform, and load data from a source to a target. In this post, we’ll walk through the process of building a robust etl (extract, transform, load) pipeline using apache airflow, google cloud storage (gcs), bigquery, and. The critical layer in the architecture is the delta.. Design and implement technical, scalable solutions by adhering to the sdlc, coding standards, best practices, code performance ensuring high quality of code. Dlt enables efficient ingestion for data engineers, python developers, data scientists and sql analysts. Kafka is a distributed streaming platform that is. The source of the data. Creation of snowflake task/pipe/stream for ingestion of data into raw layer. In this post, we’ll walk through the process of building a robust etl (extract, transform, load) pipeline using apache airflow, google cloud storage (gcs), bigquery, and. The critical layer in the architecture is the delta. Creation of snowflake task/pipe/stream for ingestion of data into raw layer of cdp (snowflake) from s3 as a source. Design and implement technical, scalable solutions. An etl (data extraction, transformation, loading) pipeline is a set of processes used to extract, transform, and load data from a source to a target. Dlt enables efficient ingestion for data engineers, python developers, data scientists and sql analysts. Data pipelines serve as the backbone of modern data architecture, facilitating the seamless flow of information from various sources to destinations. Data pipelines serve as the backbone of modern data architecture, facilitating the seamless flow of information from various sources to destinations for analysis and decision. Creation of snowflake task/pipe/stream for ingestion of data into raw layer of cdp (snowflake) from s3 as a source. Diagnose and resolve issues with etl processes, ensuring data pipelines are healthy and functional. Modern extract,. Design and implement technical, scalable solutions by adhering to the sdlc, coding standards, best practices, code performance ensuring high quality of code. An etl (data extraction, transformation, loading) pipeline is a set of processes used to extract, transform, and load data from a source to a target. Dlt enables efficient ingestion for data engineers, python developers, data scientists and sql. With this knowledge of databricks’ architecture, it’s easier to examine the details involved in building databricks etl pipelines. Kafka is a distributed streaming platform that is. Design and implement technical, scalable solutions by adhering to the sdlc, coding standards, best practices, code performance ensuring high quality of code. Extensive experience in building etl pipelines using. In this post, we’ll walk. Diagnose and resolve issues with etl processes, ensuring data pipelines are healthy and functional. The source of the data. With this knowledge of databricks’ architecture, it’s easier to examine the details involved in building databricks etl pipelines. The critical layer in the architecture is the delta. It's the series of steps and tools that automate the movement of data. An etl (data extraction, transformation, loading) pipeline is a set of processes used to extract, transform, and load data from a source to a target. With this knowledge of databricks’ architecture, it’s easier to examine the details involved in building databricks etl pipelines. Think of an etl pipeline — or etl data pipeline — as the blueprint that makes the etl process a reality. In this post, we’ll walk through the process of building a robust etl (extract, transform, load) pipeline using apache airflow, google cloud storage (gcs), bigquery, and. In a large retail chain, stakeholders must. The critical layer in the architecture is the delta. Data pipelines serve as the backbone of modern data architecture, facilitating the seamless flow of information from various sources to destinations for analysis and decision. In this comprehensive guide, we‘ll dive deep into the world of etl pipelines. Modern extract, transform, and load (etl) pipelines for data engineering have favored the python language for its broad range of uses and a large assortment of tools, applications, and open. In this blog, we will dive into the implementation of a robust etl pipeline using python, a powerful and versatile programming language that offers an array of libraries and. Creation of snowflake task/pipe/stream for ingestion of data into raw layer of cdp (snowflake) from s3 as a source. Design and implement technical, scalable solutions by adhering to the sdlc, coding standards, best practices, code performance ensuring high quality of code. It's the series of steps and tools that automate the movement of data. Extensive experience in building etl pipelines using. The focus of this blog post is to demonstrate how easily you can implement these streaming etl pipelines in apache kafka®.
Building ETL Pipelines with Python Create and deploy enterpriseready
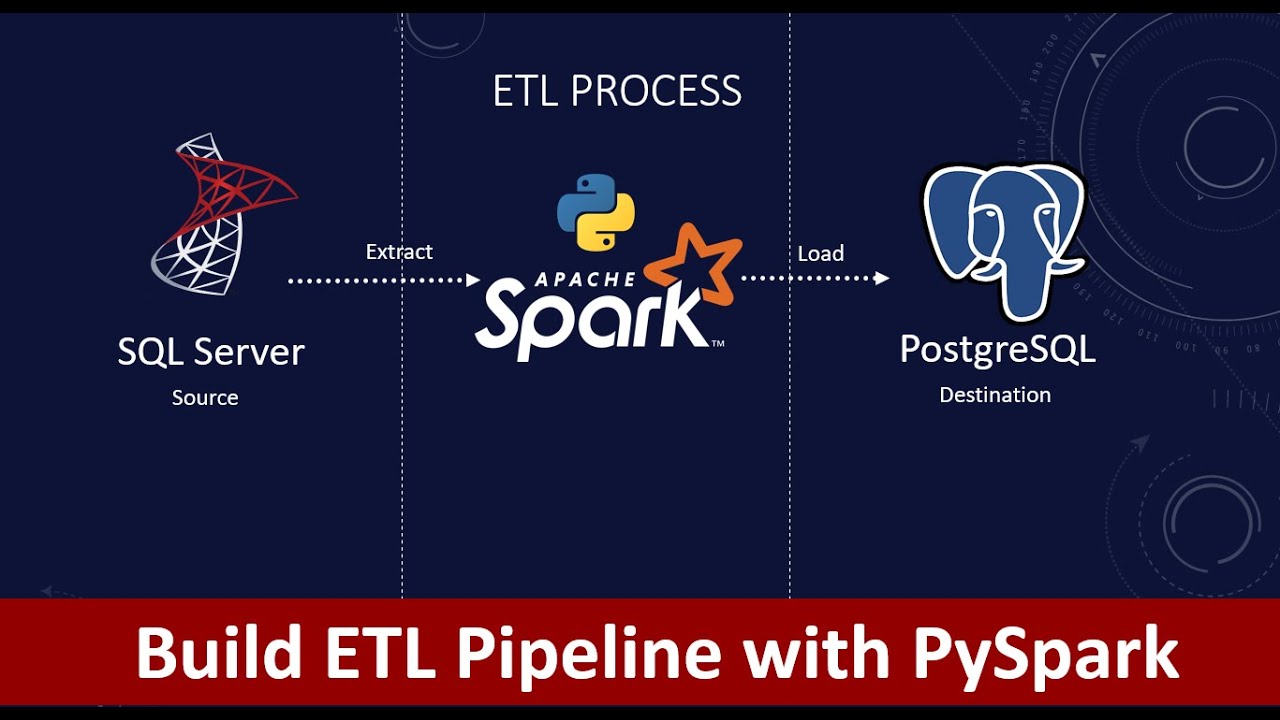
How to Build ETL Pipelines with PySpark? Build ETL pipelines on

Building serverless ETL pipelines on AWS Impetus

Building an ETL pipeline from device to cloud (bonus part)
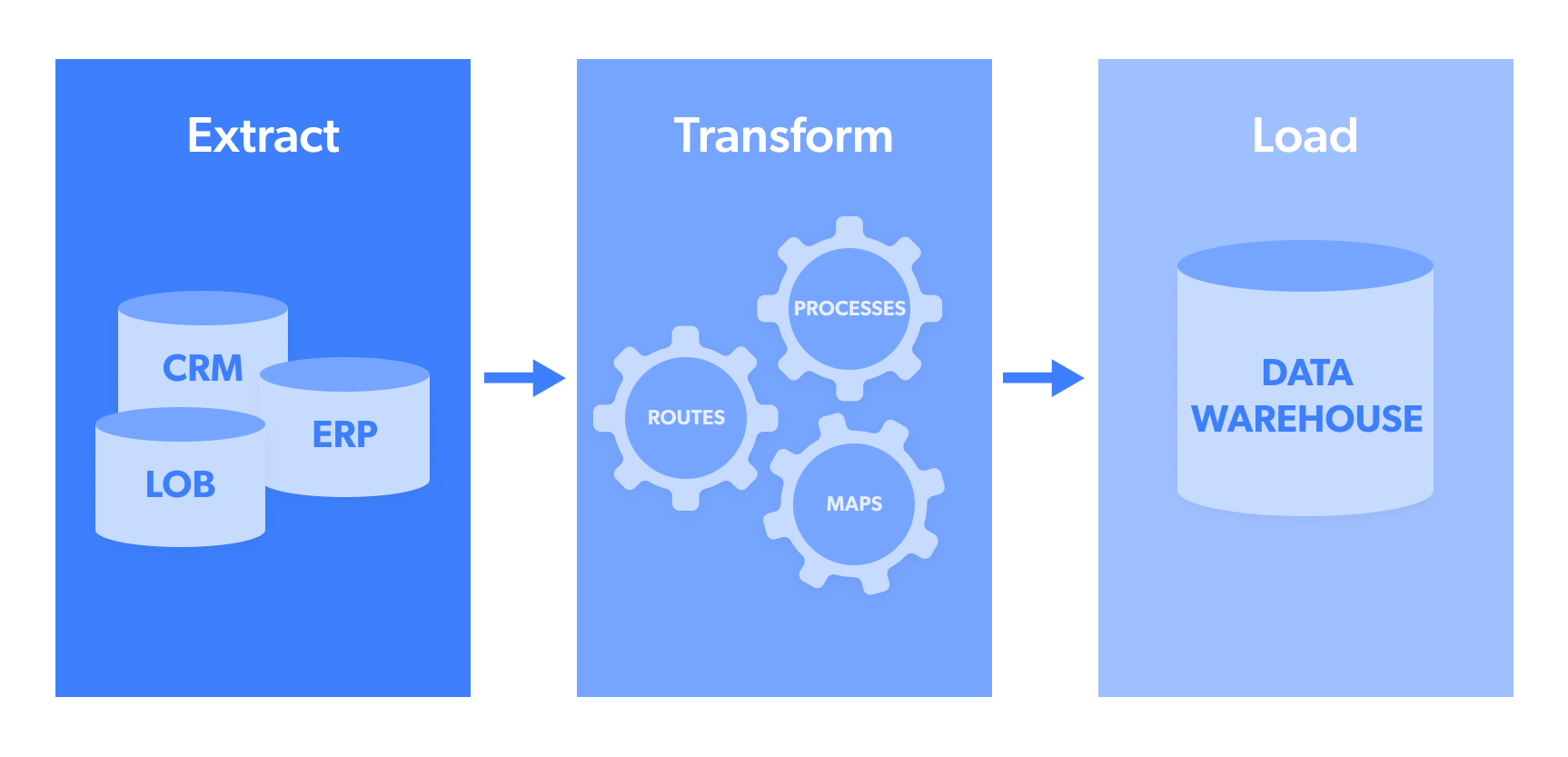
Quick Guide to Building an ETL Pipeline Process

Building Etl Pipelines In Python Part 1 Dev Community Riset
How to Build an ETL Pipeline 7 Step Guide w/ Batch Processing
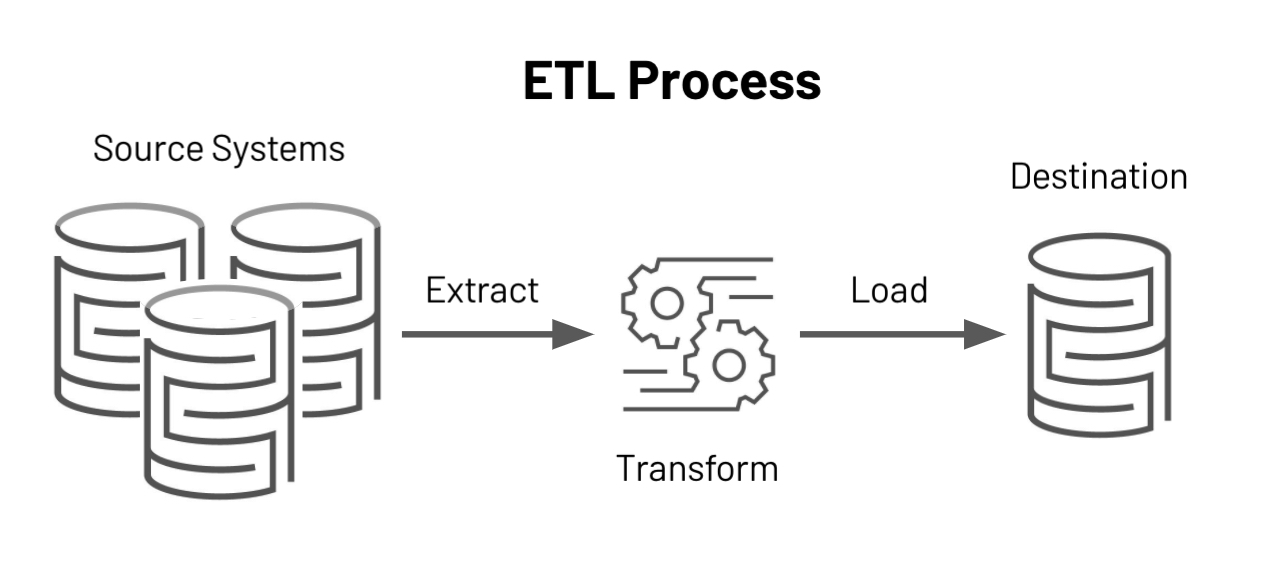
Building an ETL Data Pipeline Using Azure Data Factory Analytics Vidhya

Building ETL and Data Pipelines with Bash, Airflow and Kafka Credly
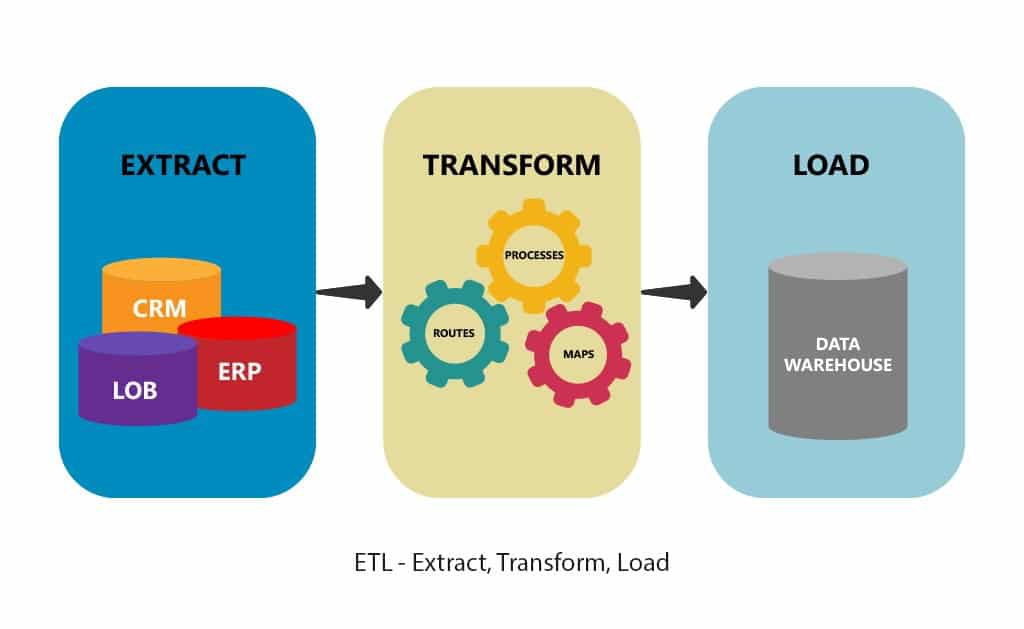
Creating ETL pipeline using Python Learn Steps
Kafka Is A Distributed Streaming Platform That Is.
The Source Of The Data.
Dlt Enables Efficient Ingestion For Data Engineers, Python Developers, Data Scientists And Sql Analysts.
Diagnose And Resolve Issues With Etl Processes, Ensuring Data Pipelines Are Healthy And Functional.
Related Post: